
ReINVenTA
O que é a ReINVenTA?

ReINVenTA é uma rede mineira de pesquisa em processamento semântico computacional de objetos multimodais. A rede, financiada pela FAPEMIG (processo RED-000106/21) e CNPq (processo 420945/2022-9), vem reunindo projetos de pesquisa que se dedicam a construir e avaliar modelos computacionais de representação de objetos como programas de TV e pareamentos de imagens estáticas e texto. Para tanto, mobilizou laboratórios e grupos de pesquisa da UFJF, UFMG, UFU, PUC-MG, UFPB, Case Western Reserve University e Universitat Leipzig, com expertise em Desenvolvimento de Modelos para Processamento de Língua Natural, Inteligência Artificial Multimodal, Descoberta de Conhecimento e Tecnologias Assistivas. Com essa confluência de expertises e projetos a rede ReINVenTA buscou alcançar:
Qual a natureza do dataset produzido?
Para que modelos de IA alcancem precisão semântica, a existência de datasets curados por humanos é indispensável. A ReINVenTA desenvolveu uma base de dados que alinha bounding boxes e textos verbais anotados para frames semânticos, permitindo que máquinas “entendam” cenas complexas e não apenas identifiquem objetos isolados.
A constituição do dataset ReINVenTA é caracterizada pela integração de quatro subconjuntos específicos de dados multimodais padrão ouro: o Framed Multi30K, o Frame², o Audition e o FramedNews, todos eles disponibilizados gratuitamente para uso não comercial através de licença CC 4.0-NC-BY.
Framed Multi 30k
O dataset Framed Multi30K (FM30K) (Viridiano et al., 2024) é um recurso multimodal e multilingue baseado na Semântica de Frames, desenvolvido para o português brasileiro. Ele surge para suprir a carência de representações semânticas refinadas em datasets multimodais tradicionais, que geralmente carecem de meios para representar informações contextuais detalhadas. O FM30K expande os datasets internacionais Flickr 30K, Multi30K e Flickr30K Entities através de três frentes principais: a adição de descrições em português, a rotulação semântica massiva de textos e a correlação de frames a regiões específicas de imagens.
O Flickr30K é um dataset que reúne cerca de 30 mil imagens às quais estão associadas cerca de 150 mil descrições produzidas originalmente em inglês (sendo 5 para cada imagem). O Multi30K adicional descrições originais em outras línguas (e.g. alemão, francês, checo) ao Flickr30K, trazendo também traduções de uma descrição por imagem. Já o Flickr30K Entities associa a cada uma das imagens bounding boxes que indicam quais entidades mencionadas nas descrições aparecem nas imagens.
Expansão Textual para o Português Brasileiro
A primeira grande contribuição do FM30K é a inclusão do português brasileiro na família Multi30K, adicionando um total de 189.919 descrições em português brasileiro ao dataset. Esse volume divide-se em duas categorias:
Descrições Originais (PTO): Foram criadas 158.915 novas descrições independentes em português brasileiro, seguindo a metodologia de cinco sentenças por imagem para as 31.783 fotos do Flickr30K. Essas descrições foram produzidas por 148 estudantes universitários nativos, capturando uma maior variedade de perspectivas sobre as cenas. As descrições foram produzidas usando-se uma interface desenvolvida pela ReINVenTA, conforme Figura 1.
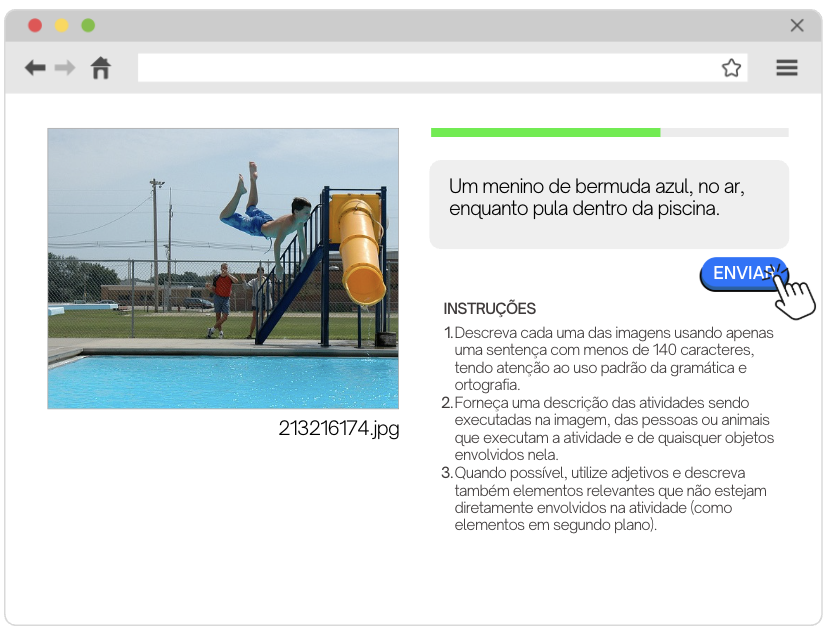
Figura 1: Interface de criação de descrições originais em PB
Traduções (PTT): Foram realizadas 31.104 traduções do inglês para o português brasileiro, alinhadas com as traduções preexistentes em alemão, francês e tcheco do Multi30K. Esse trabalho foi executado por tradutores com proficiência avançada em inglês, usando-se a interface mostrada na Figura 2, e passou por rigorosos controles de qualidade manuais e automatizados.
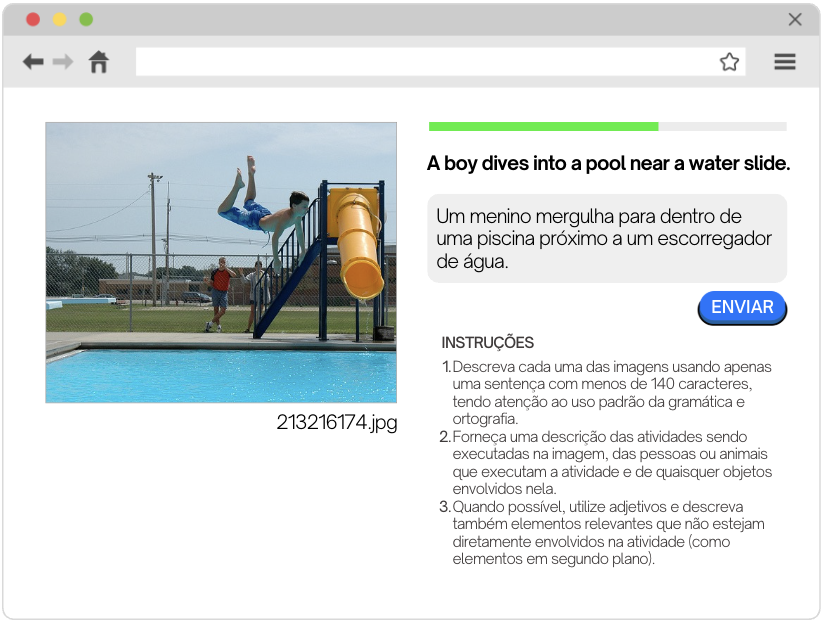
Figura 2: Interface de criação de traduções
Enriquecimento Semântico Automático (LOME)
Para dotar o dataset de informações semânticas explícitas, utilizou-se o sistema LOME (Large Ontology Multilingual Extraction), um parser treinado em dados da Berkeley FrameNet e da FrameNet Brasil. O sistema realizou a rotulação automática de papéis semânticos em todas as 158.915 descrições originais em inglês, além das novas descrições (PTO e PTT) em português. Ao todo, foram adicionadas 4.577.122 etiquetas de frames e elementos de frame às sentenças. Em média, cada sentença em português (PTO) recebeu cerca de 13,4 etiquetas semânticas, demonstrando a granularidade do recurso. Um exemplo de anotação automática feita pelo LOME é mostrado na Figura 3.
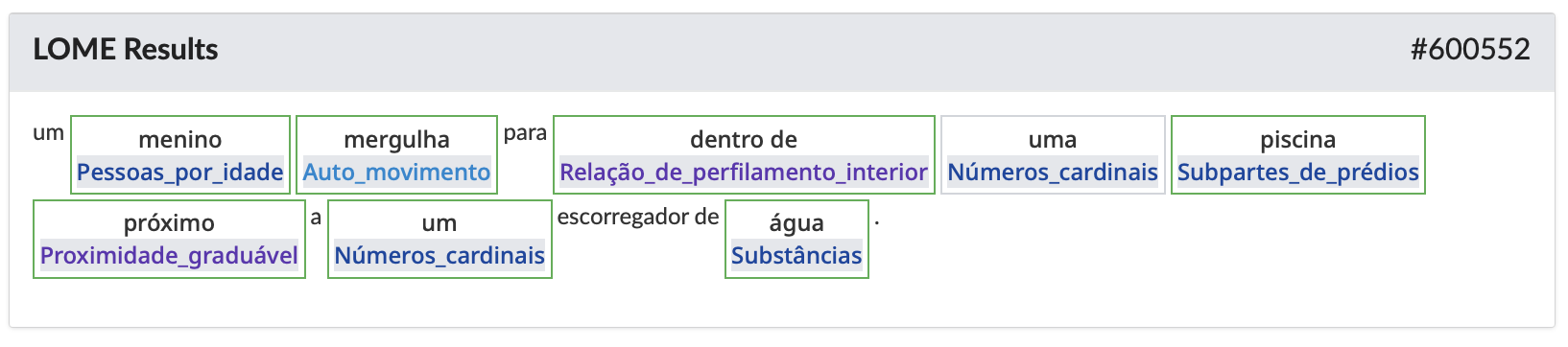
Figura 3: Anotação automática realizada pelo LOME
Anotação Humana de Imagens
O FM30K enriquece o dataset Flickr30K Entities ao adicionar 169.560 correlações entre frames/elementos de frame e as bounding boxes já existentes nas imagens. Utilizando a ferramenta WebTool (Figura 3), anotadores humanos associaram categorias da FrameNet a entidades visuais em 29.831 conjuntos de imagens.
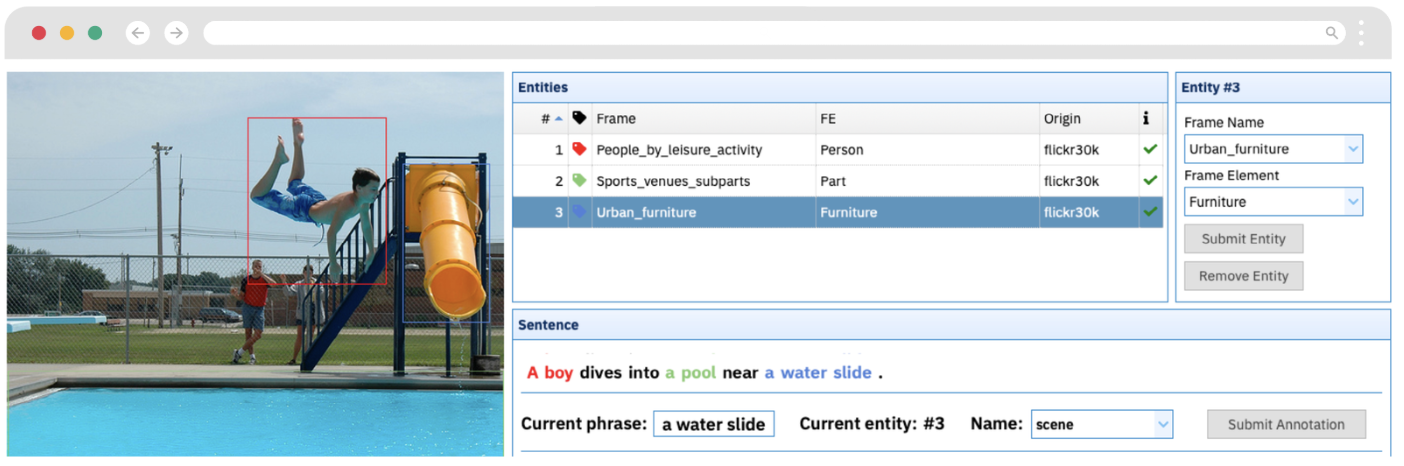
Figura 4: Anotação de imagens no FM30K
Essa tarefa foi conduzida sob duas condições experimentais:
Com Legenda (VWC): O anotador via a imagem e a descrição textual correspondente, o que restringia o número de interpretações possíveis e aproximava a semântica da imagem à do texto.
Sem Legenda (VNC): O anotador via apenas a imagem, permitindo capturar como o contexto puramente visual influencia a percepção semântica.
Como usar
O FM30K consolida-se como um benchmark para tarefas de Rotulação de Imagens, Tradução Automática Multimodal e Descrição Automática de Imagens. Ele fornece metadados semânticos que podem melhorar tarefas de detecção de objetos e resolução de correferência. O dataset é público e está disponível no repositório da FrameNet Brasil.
Baixe o dataset.
Frame²
Composto pelos dez episódios da primeira temporada do TV Travel Series Pedro pelo Mundo, exibido pelo canal GNT, o Frame² (Belcavello et al., 2024) foi anotado para frames, elementos de frames e categorias de objetos reconhecíveis por algoritmos de visão computacional para as modalidades de vídeo, áudio original e legendas.
O principal objetivo do Frame² é oferecer um recurso semântico bastante granular e enriquecido para tarefas de Processamento de Língua Natural (PLN) multimodal. A premissa central é que imagens e seus elementos, de forma equivalente ao material linguístico, podem evocar frames ou trabalhar em conjunto com o texto verbal na construção de sentido. O dataset reflete a estrutura da base de dados da FrameNet Brasil (Torrent et al., 2022), incluindo informações sobre frames, elementos de frame (EFs), relações entre frames e relações entre unidades lexicais (ULs).
Composição do Corpus e Pré-processamento
O corpus selecionado compreende os dez episódios da primeira temporada da série “Pedro pelo Mundo” (GNT, 2016), totalizando 230 minutos de vídeo. O programa foca em aspectos sociais, econômicos e culturais de locais em transformação, misturando sequências de narração em voice-over, entrevistas e clipes musicais.
Figura 5: Pipeline de pré-processamento do Frame2
O pipeline de processamento (vide Figura 4) envolveu a extração de dois tipos de arquivos principais para anotação semântica:
Arquivos de texto: Contendo as transcrições do áudio original e as legendas de segmentos onde o apresentador realiza entrevistas em inglês.
Arquivos de imagem: Extraídos a uma taxa de 25 quadros por segundo. Ao final, o corpus resultou em 2.195 sentenças transcritas.
Os arquivos dos dois tipos foram indexados para time stamps, de modo que o alinhamento entre os modos comunicativos pudesse ser mantido no dataset resultante ao final do trabalho de anotação semântica multimodal.
Metodologia de Anotação
A tarefa de anotação foi dividida em duas frentes integradas:
Anotação de Texto: Seguiu as diretrizes da FrameNet para anotação de texto corrido (full-text annotation), criando Conjuntos de Anotação (AS) para cada palavra que possui uma Unidade Lexical na base.
Anotação de Vídeo: Utilizou ferramenta que permite correlacionar objetos visuais com dados textuais. Nesta etapa, o anotador delimita uma caixa delimitadora (bounding box) na imagem, que é entendida como a manifestação visual de um elemento de frame.
Um diferencial importante é a categorização CV Name, criada para alinhar o objeto visual a categorias pré-treinadas de visão computacional (baseadas no Open Images Dataset v6). Por exemplo, em uma cena sobre “grafite” (Figura 5), o objeto pode ser anotado visualmente como o elemento Behavior no frame de Mental_property (devido ao contexto da narração), enquanto o seu CV Name seria “grafite.n” no frame Physical_artworks.
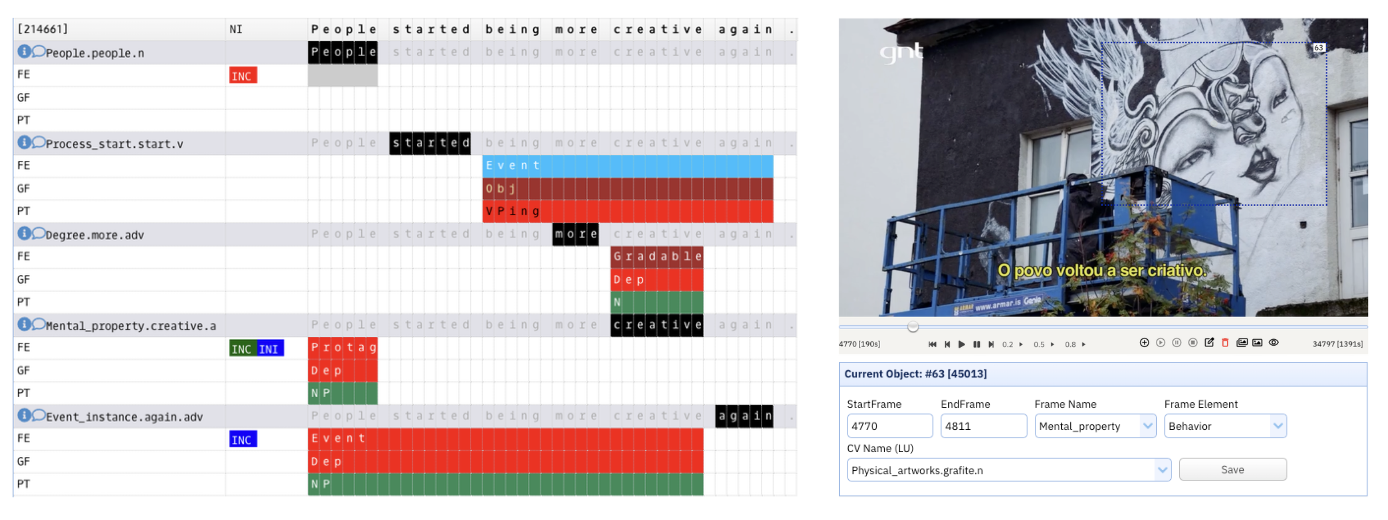
Figura 6: Anotação multimodal no Frame2
Resultados e Estatísticas do Dataset
A primeira versão do Frame² apresenta os seguintes números consolidados:
2.195 sentenças anotadas.
11.796 conjuntos de anotação (AS) para texto (média de 5,36 AS por sentença).
6.841 objetos visuais (VOs) anotados no vídeo.
Em termos de diversidade semântica, o dataset mobiliza:
611 frames discretos na anotação textual.
393 frames discretos na anotação de imagem.
478 unidades lexicais distintas utilizadas como CV Name.
A variabilidade de frames no texto é maior do que na modalidade visual. Além disso, a taxa de correspondência entre o frame do objeto visual e o frame do CV Name é de apenas 1,61%, o que significa que 98,39% dos objetos visuais estão associados a dois frames diferentes, indicando que são objetos semanticamente enriquecidos desde a base.
Novos desdobramentos
A partir da primeira versão do Frame², novos esforços de anotação tem sido realizados. Partindo do trabalho de Sigiliano (2025) sobre mudanças de centro dêitico em narrativas fílmicas, os episódios da série Pedro pelo Mundo foram anotados também para categorias que indicam as pistas linguísticas e visuais que sinalizam ao espectador que o assunto abordado pelo vídeo mudou. Já o trabalho de Abreu & Matos (2025) explorou a aporte semântico trazido pelos gestos usados pelo apresentador e seus entrevistados.
Como usar
O dataset Frame² é pioneiro ao combinar a Semântica de Frames com a anotação de vídeo dinâmico. Ele permite que a FrameNet diversifique suas formas de representação, incorporando a imagem como um elemento ativo na construção de significado, mantendo sempre a ancoragem linguística.
Baixe o dataset.
Audition
O dataset Audition é um recurso multimodal padrão ouro focado na análise semântica de curtas-metragens brasileiros acessíveis. Conforme detalhado em Gamonal et al. (2025), o dataset foi concebido para preencher uma lacuna no PLN e nas tecnologias assistivas, que frequentemente ignoram a natureza inerentemente multimodal da comunicação humana.
A principal motivação do Audition é o domínio da Tradução Audiovisual Acessível. Para criar mídias inclusivas, são necessários sistemas capazes de interpretar e gerar sentido entre diferentes modalidades, especialmente para apoiar usuários com deficiência visual. O dataset permite investigar como o sentido é transposto entre o áudio original, a audiodescrição (AD) e o conteúdo visual, provendo dados estruturados para o treinamento de modelos de IA voltados à acessibilidade.
Composição do Corpus e Modos Comunicativos
O dataset Audition abrange diversos gêneros cinematográficos, incluindo animação, documentário, ficção, performance e autobiografia. Em sua versão completa, o recurso compreende mais de 240 minutos de material audiovisual.
O dataset cobre uma vasta gama de modos comunicativos:
Áudio Original (OA): Diálogos e narrações originais da trilha sonora.
Audiodescrição (AD): Narração adicional roteirizada que verbaliza informações visuais (ações, gestos, cenários, estados emocionais).
Conteúdo Visual (VC): O fluxo de imagens segmentado em cenas e planos narrativos.
Outros: Legendas, Closed Captions (CC) e textos sobrepostos na tela (text-overlays).
Metodologia de Anotação
A anotação seguiu a metodologia de texto corrido da FrameNet, complementada pelas diretrizes multimodais da FN-Br. Utilizou-se a ferramenta WebTool, que permite a visualização sincronizada das modalidades e a atribuição de frames e elementos de frame (EFs) a segmentos de texto ou regiões do vídeo.
Anotação Verbal (OA e AD): Baseia-se em Unidades Lexicais (ULs) identificadas na fala.
Anotação de Vídeo (VC): Segue uma abordagem orientada ao texto, onde os anotadores utilizam as transcrições para guiar a marcação de bounding boxes (caixas delimitadoras) no vídeo.
No exemplo mostrado na Figura 7, enquanto na audiodescrição enuncia-se a sentença “Vira um tubo de ensaio em um recipiente com líquido roxo”, vê-se na tela a imagem do tubo, que foi anotada para o frame de Manipulação, e para o EF Entidade.
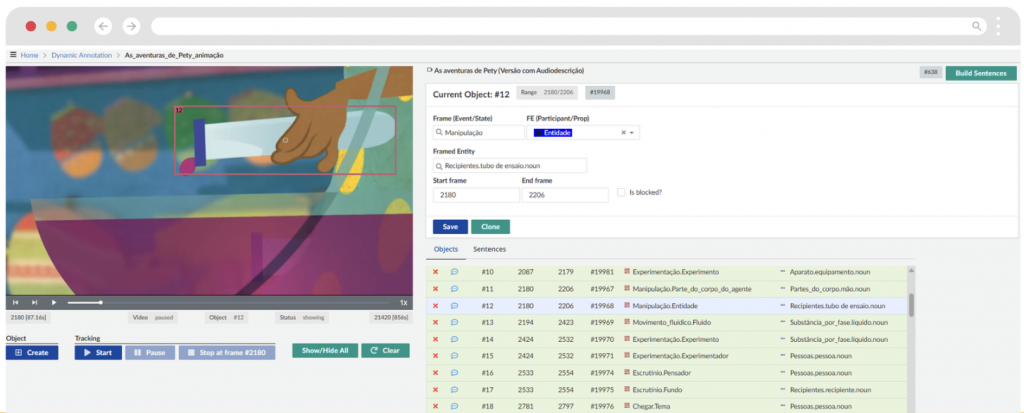
Figura 7: Anotação multimodal no Audition
Estatísticas e Resultados do Dataset
O subconjunto de dados resultou em:
894 sentenças (464 de áudio original e 430 de audiodescrição).
3.979 conjuntos de anotação semântica.
8.189 elementos de frame identificados.
1.103 caixas delimitadoras (semantic boxes) no conteúdo visual.
Como usar
O dataset Audition demonstra a eficácia da Semântica de Frames para modelar o sentido em contextos multimodais complexos. Como contribuição central, fornece uma métrica de similaridade baseada em modelos cognitivos, com implicações diretas para a avaliação de recursos de acessibilidade.
Baixe o dataset.
FramedNews
O FramedNews é o mais recente dos datasets da ReINVenTA e seu desenvolvimento foi possível pela concessão de duas bolsas de pós-doutorado no exterior pelo CNPq (processo 402740/2022-0). O FramedNews tem por objetivo expandir a cobertura da ReINVenTA para o domínio jornalístico. É composto, portanto, por dois subsets:
Portais de notícias: o primeiro subconjunto dados é composto de 6.787 pareamentos de foto, manchete e texto de chamada (trecho de texto que desenvolve algum aspecto da mensagem) de notícias jornalísticas disponibilizadas em portal na internet.
Reportagens telejornalísticas: o segundo subconjunto é composto de 131 minutos de reportagens veiculadas em telejornal, correspondentes a 1.157 sentenças de áudio transcrito.
Uma nova fronteira no desenvolvimento de datasets: uso de IA para semi-automatização de processos
Para além de expandir a cobertura da ReINVenTA para o domínio jornalístico, o FramedNews buscou também avaliar em que medida etapas do processo de criação de datasets multimodais anotados para frames poderiam ser semi-automatizadas com o uso de modelos de IA.
Para o subconjunto relativo ao conteúdo disponibilizado em portais de notícias (cujo uso foi devidamente autorizado), o uso de ferramentas de IA começou no pré-processamento do corpus. A construção de datasets de alta qualidade, curados por humanos, para aprendizado de máquina exige esforço significativo tanto na rotulagem quanto na validação dos dados, sendo essa etapa uma das mais caras e demoradas do processo. Nesse contexto, a expansão por IA generativa buscou reduzir esse custo ao produzir anotações iniciais em larga escala, posteriormente validadas por especialistas. Optou-se pelo Gemma 3 12B por seu caráter open-source, capacidade multimodal e eficiência, e pelo GroundingDINO por permitir detecção aberta de objetos a partir de descrições textuais. O pipeline processou aproximadamente 13 mil imagens jornalísticas em três etapas:
um modelo de língua extraiu descrições estruturadas bilíngues, entidades anotadas e interpretações de eventos;
o GroundingDINO usou essas entidades para gerar bounding boxes e localizar objetos;
LOME e DAISY atribuem frames e elementos de frame às regiões detectadas.
Por fim, os dados passam por pós-processamento e validação humana, resultando em um dataset multimodal estruturado e semanticamente anotado. As tarefas de validação envolveram a revisão de anotações automáticas, incluindo frames, elementos de frame e sua relação com entidades visuais. O processo ocorreu em três etapas:
validação dos frames atribuídos às entidades detectadas pelo GroundingDINO;
correlação entre itens lexicais do título/excerto e essas entidades;
validação dos frames atribuídos por LOME e DAISY.
Um esquema do pipeline é mostrado na Figura 8.
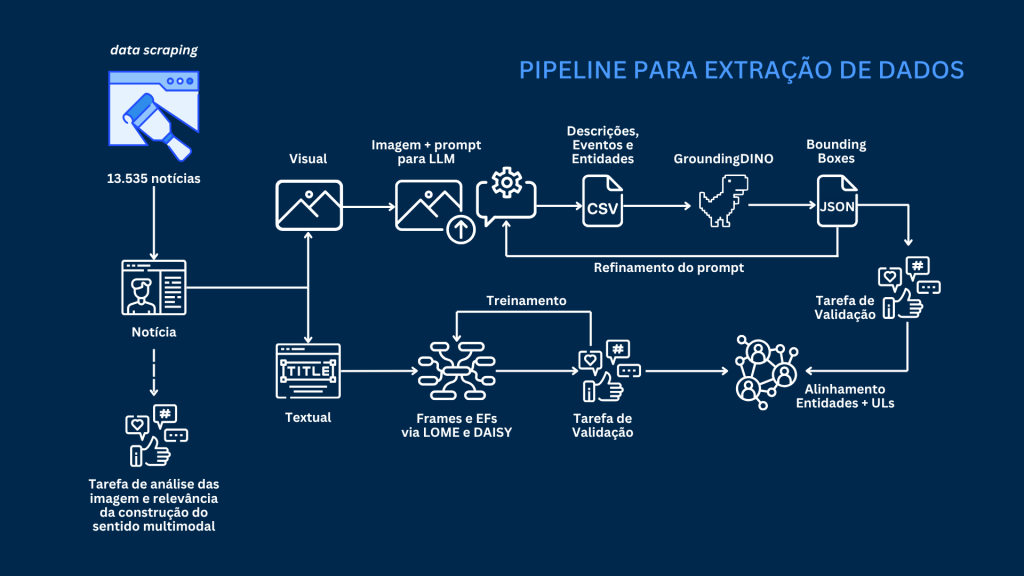
Figura 8: Pipeline de IA para constituição do subset de portais de notícias
Já para o subset relativo às reportagens telejornalísticas, o uso de IA concentrou-se em outra frente: uma vez que os dados de vídeo e audio transcrito estavam prontos para a anotação, seguindo a mesma metodologia utilizada nos datasets Frame² e Audition, foi montada uma tarefa de pré-anotação semântica das transcrições de áudio (vide Belcavello et al., 2026).
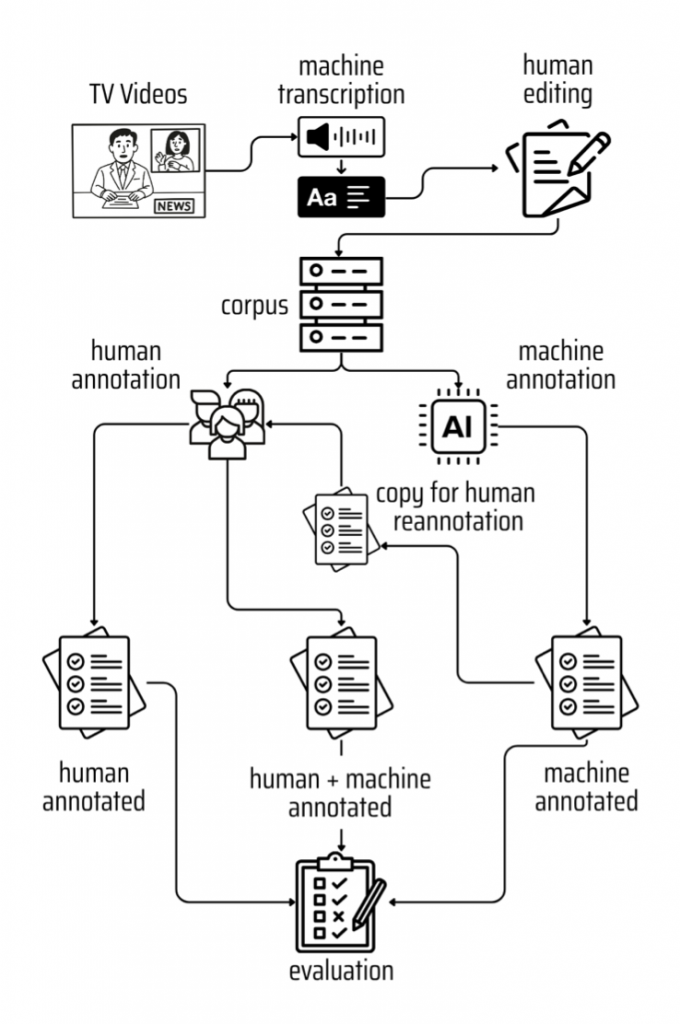
Figura 9: Desenho experimental usado na anotação semi-automatizada das reportagens telejornalísticas
Os dados foram organizados para testar três cenários de anotação:
um feito de forma manual por humanos;
um feito inteiramente pela máquina;
um formato híbrido envolvendo a máquina e o humano.
No cenário de anotação puramente humana, um grupo de cinco anotadores com experiência na tarefa analisou cerca de 60 sentenças cada, criando as anotações manualmente a partir do zero. Paralelamente, no cenário focado na máquina, utilizou-se o LOME para anotar as sentenças.
A etapa híbrida consistiu em unir a tecnologia ao conhecimento dos especialistas. Nesse momento, os mesmos anotadores humanos receberam um novo conjunto de frases que já traziam as sentenças pré-anotadas pelo LOME. O objetivo da equipe foi revisar e corrigir essas sugestões geradas automaticamente. Durante essa curadoria, eles tinham a liberdade de aceitar totalmente a anotação feita pela IA, rejeitar e apagar completamente a sugestão se estivesse incorreta, modificar ou atualizar os rótulos sugeridos, ou ainda criar novas anotações que o sistema havia ignorado. Todo esse desenho foi planejado com o intuito de comparar os métodos em termos de velocidade, diversidade e aderência rigorosa à metodologia.
Os resultados demonstram que delegar a tarefa inteiramente para a máquina resulta em um desempenho consideravelmente inferior em qualidade e detalhamento. Em contrapartida, o formato semiautomático mostrou-se um caminho bastante viável e promissor. Embora a assistência da IA não tenha provocado uma redução significativa no tempo total de anotação , a parceria entre máquina e humano estimulou o uso de uma diversidade maior de frames, ampliando a cobertura dos dados enquanto preservou o rigor e o julgamento crítico indispensáveis aos especialistas.
Estatísticas e Resultados do Dataset
O subconjunto de dados resultou em:
1.157 sentenças extraídas de reportagens telejornalísticas, anotadas semi-automaticamente e validadas por humanos.
6.787 manchetes de jornal anotadas automaticamente e validadas.
6.787 chamadas para notícias anotadas automaticamente e validadas.
131 minutos de vídeo anotados manualmente.
6.787 imagens anotadas automaticamente e validadas.
Como usar
O dataset FramedNews inaugura uma nova metodologia para a constituição de datasets multimodais que alia a necessária curadoria humana ao poder de escalamento da IA.
Baixe o dataset.
Como saber se as anotações realizadas são representativas?
A validação psicolinguística do dataset da ReINVenTA foi estabelecida como uma das metas centrais para verificar se os objetos visuais selecionados para anotação são, de fato, proeminentes do ponto de vista do espectador/leitor. Para o dataset Frame² esse processo foi realizado por meio de experimentos de eye-tracking (rastreamento ocular) conduzidos no laboratório NEALP (UFJF), utilizando softwares especializados para monitorar a fixação ocular. O objetivo principal do experimento foi checar se as áreas anotadas manualmente na modalidade visual dos corpora concentram os pontos de fixação dos espectadores durante a exibição dos vídeos.
Compararam-se os padrões de fixação de olhar de grupos expostos a versões integrais de um programa televisivo frente a versões com supressão de áudio. Embora a hipótese inicial sugerisse que a fala exerceria um papel preponderante no direcionamento do olhar e na organização do sentido, os resultados indicaram que sua influência é sutil. Evidenciou-se que a linguagem cinematográfica — compreendendo enquadramentos, movimentos de câmera e composição de imagem — possui maior eficácia na determinação dos padrões de atenção visual. Tais achados reiteram a necessidade de uma análise integrada dos modos comunicativos, sugerindo que a evocação de frames em ambientes multimodais deve considerar o dado como um todo indissociável, composto pela síntese entre o material textual e o visual.
Além de validar a qualidade do dataset padrão ouro, os resultados desses experimentos serviram como referência, também para os trabalhos voltados para a audiodescrição, orientando a seleção de elementos visuais que devem ser priorizados por serem naturalmente mais percebidos pelo público vidente.
E o que foi feito com esses datasets?
A ReINVenTA também se propôs desenvolver modelos de IA para rotulação semântica de imagens. Após uma série de testes com modelos de prateleira, chegamos à conclusão de que uma técnica inovadora de treinamento precisaria ser buscada.
Desenvolvimento do Rotulador Semântico Multimodal: a Fusão Neuro-Simbólica
Nosso principal objetivo foi criar um sistema capaz de “olhar” para uma imagem e entender profundamente o que está acontecendo nela. Queríamos que a inteligência artificial não apenas identificasse objetos soltos, mas compreendesse eventos (os cenários ou Frames da FrameNet) e as entidades envolvidas.
Para alcançar esse nível de complexidade, adotamos o estado da arte em Foundation Models e Fusão Neuro-Simbólica. Essa união foi fundamental para superar um dos maiores desafios do projeto: lidar com o chamado Small Data (quando temos pouquíssimos dados anotados para ensinar a máquina).
Infraestrutura e Estratégia
Toda a experimentação rodou em um ambiente de alta performance (um servidor vm-281 com GPU NVIDIA A30), usando ferramentas estritamente controladas para garantir que qualquer pessoa pudesse reproduzir os testes (Python 3.9 via conda, com as bibliotecas torch==2.1.0, torchvision==0.16.0 e transformers==4.35.2), e o dataset Framed Multi30K.
A estratégia foi dividida em estágios:
Detecção (Estágio 1): Testamos três versões do modelo YOLOv8 (Nano, Small e Medium) para encontrar bounding boxes ao redor dos objetos. A versão YOLOv8 Medium teve o melhor desempenho, atingindo a métrica mAP50-95 de aproximadamente 2.9%. Pode parecer baixo, mas na prática o modelo foi ótimo para detectar coisas comuns (como pessoas e animais), sofrendo apenas com classes muito raras devido à falta de exemplos.
Refinamento Visual (Estágio 2): Depois de detectar o objeto, recortamos a imagem (crops) e usamos o modelo Vision Transformer (ViT-Base-32) para classificá-lo. Alcançamos uma Acurácia Global de 47.5% (chegando a uma acurácia de 55.9% nas 20 categorias mais frequentes). A máquina frequentemente confundia classes específicas (como “Pessoa por profissão”) com a classe genérica (“Pessoa”) porque faltava contexto ao redor do recorte.
Compreensão do Evento (Estágio 3): Entender o evento de uma cena inteira é muito mais difícil do que achar um objeto.
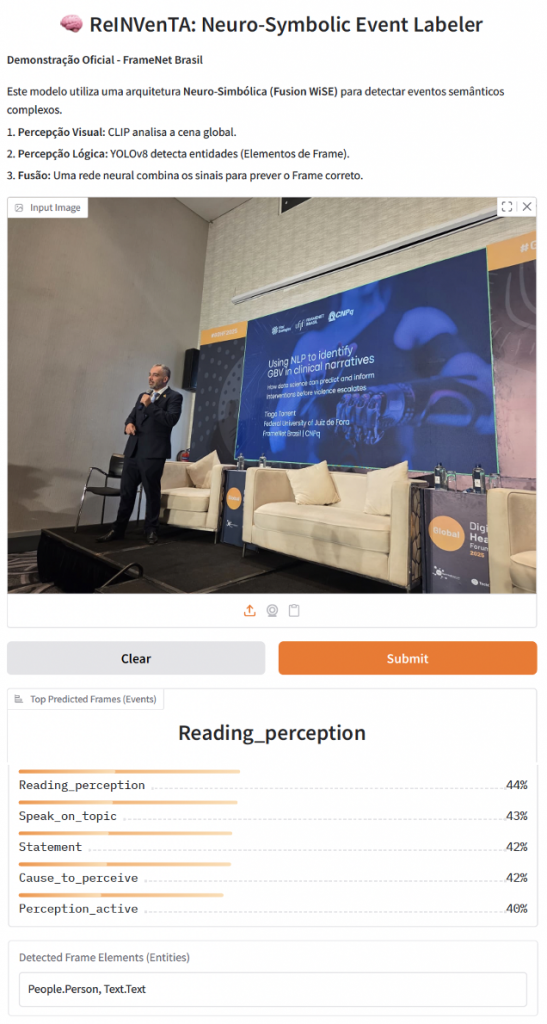
Figura 10: Modelo de IA para rotulação semântica de imagens desenvolvido pela ReINVenTA
Para alcançar o estágio 3, buscou-se, primeiramente, usar um ViT Global para prever o evento olhando para a imagem toda de uma vez. O modelo obteve um F1-Score de 0.00%., ou seja, indicou que “nenhum evento” estava acontecendo, provando que apenas analisar pixels não resolve o problema do Small Data.
Na sequência, criamos um classificador tabular simples, um MLP (MultiLayer Perceptron) chamado de modelo “Join”, que analisava apenas a lista de entidades detectadas e tentava inferir o evento a partir delas. O resultado foi um F1-Micro de 8.42%, que ainda era modesto, mas muito superior à visão pura, provando que a lógica das entidades é essencial.
No passo seguinte, usamos o CLIP 32-B e testamos o modelo no formato CLIP Zero-Shot (sem treinamento adicional, apenas comparando a similaridade semântica entre a imagem e o nome do evento). O resultado saltou para um Recall@5 de 11.32% e um ROC AUC de 0.69. Quando aplicamos a técnica de Linear Probing sobre o modelo, o F1-Micro foi para 11.72%.
Isso abriu caminho para uma solução que unisse as técnicas mais promissoras: Fusion WiSE (Weight-Space Ensemble). Ela concatena o vetor de visão do CLIP com a lista de entidades detectadas pelo YOLO. Usamos a técnica WiSE-FT para inicializar o conhecimento semântico da máquina e aplicamos a função Asymmetric Loss (ASL) para focar nos erros mais difíceis e ignorar as penalidades bobas. Como resultado, o Recall@5 subiu para 68.1%.
No exemplo da Figura 10, vemos como o modelo foi capaz de inferir os frames de evento adequados para a foto enviada.
O modelo resultante está disponível publicamente como Open-Source.
Acesso o demo do modelo.
O que mais foi produzido?
A partir das análises realizadas na constituição do dataset Audition, foi produzido o Guia ReINVenTA para a Audiodescrição Fílmica (formato PDF, tamanho 10MB), que reúne, em um guia prático, contribuições da tecnologia linguística para a experiência cinematográfica acessível. A metodologia defende que o foco da audiodescrição não deve ser apenas a descrição fria dos elementos visuais, mas a garantia de que os elementos descritos ativem no público os mesmos pacotes de conhecimento e as mesmas emoções planejadas pela obra original. Essa tensão repensada entre objetividade e interpretação permite recriar a experiência cinematográfica com muito mais riqueza e profundidade.

Guia ReINVenTA para a Audiodescrição Fílmica
Além de fundamentar uma nova prática de redação, o Guia ReINVenTA olha para o futuro da produção audiovisual. O material aborda o impacto da Inteligência Artificial no setor, avaliando como ferramentas de visão computacional podem dar suporte ao fluxo de trabalho do audiodescritor. O objetivo é criar infraestrutura para que a produção de conteúdos acessíveis ganhe escala sem perder a plausibilidade cognitiva e a precisão linguística.
O Guia ReINVenTA para a Audiodescrição Fílmica já está disponível e é voltado para audiodescritores, pesquisadores de acessibilidade, produtores de conteúdo e estudantes de comunicação e audiovisual.
Qual o status atual do projeto?
A ReINVenTA prossegue criando novos datasets e melhorando seus modelos de IA. Na fase atual, ela passa a alimentar o eixo de Recursos Linguísticos do recém-criado Instituto Nacional de Ciência e Tecnologia em Inteligência Artificial Responsável para Linguística Computacional, Tratamento e Disseminação de Informação: INCT-TILDIAR. Além disso, é possível acessar o Dashboard da ReINVenTA para acompanhar o progresso da anotação em tempo real.