
Por Profa. Camila Borelli Zeller
Este press release apresenta os principais achados do artigo “When words collide: Are statistics and data science two professions separated by a common language?”, publicado na revista Significance (2025). O artigo discute o crescente distanciamento linguístico entre estatísticos e cientistas de dados, mesmo quando trabalham com os mesmos métodos e conceitos. Embora as áreas compartilhem fundamentos matemáticos, elas desenvolveram vocabulários distintos, criando ruídos de comunicação que podem prejudicar ensino, pesquisa, colaboração e tomada de decisão.
O “choque de linguagem”: por que acontece?
A diferença terminológica surge porque Estatística, Ciência da Computação e Engenharia evoluíram de forma independente. Quando convergiram sob o guarda-chuva da “Ciência de Dados”, carregaram consigo suas tradições linguísticas. Exemplo clássico: Ridge Regression (estatística) = Weight Decay (ciência de dados). Mesma matemática, nomes diferentes, reflexos de tradições distintas. Essa divergência contribui para a impressão de desacordo entre especialistas, mesmo quando tratam do mesmo conceito.
Consequências práticas
As diferenças de terminologia têm impactos concretos em diversos setores.
- Na educação: Estudantes têm dificuldade para conectar o que aprendem em cursos clássicos de Estatística ao que aparece em bootcamps e formações típicas de Ciência de Dados.
- No ambiente profissional: Equipes multidisciplinares podem interpretar termos iguais de forma diferente, ou termos diferentes como equivalentes, levando a atrasos e retrabalho.
- Na avaliação de projetos: Métodos estatísticos clássicos podem ser desvalorizados frente a termos como “IA”, ainda que representem modelos equivalentes. Exemplo citado: regressão linear ser vista como “simples”, enquanto um “neurônio único” recebe mais entusiasmo.
- Na comunicação com não especialistas: Termos como intervalo de confiança e intervalo de predição são frequentemente confundidos, afetando decisões práticas.
Tabela comparativa (“Rosetta Stone”)
O artigo apresenta também um mapeamento de termos usados em Estatística e seus equivalentes na Ciência de Dados. Entre os exemplos destacados, estão as correspondências entre “Ridge regression” e “Weight decay”, “Lasso” e “L1 regularization”, além de “Preditor” e “Feature”, “Resposta” e “Target/Label”, “Resíduos” e “Prediction errors”. Os autores mencionam ainda que o método estatístico “MLE” corresponde, na prática de Ciência de Dados, à noção de “loss minimization”, e que o conceito de “confounding” se relaciona ao que profissionais de Ciência de Dados chamam de “feature leakage”. A Tabela a seguir é um enxerto do artigo: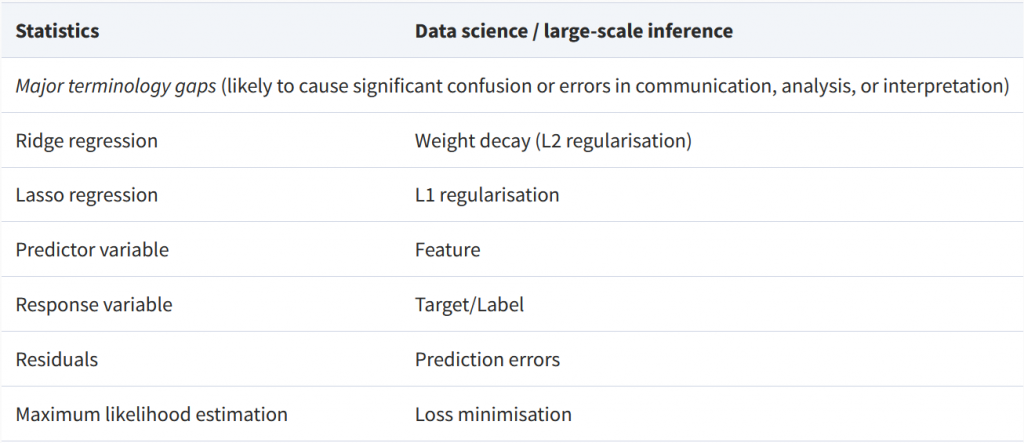
Causas culturais
As diferenças também derivam de fatores culturais, tais como estatísticos evitam jargões desnecessários e cientistas de dados valorizam termos novos e impacto. Adicionalmente, palavras como “bias” são ótimos exemplos de termos com significados técnicos distintos, cujo sentido depende totalmente do contexto. Por exemplo, em Inferência Estatística, tem-se estimadores não viesados; em Ciência de Dados, o termo está ligado à capacidade de ajuste do modelo; em Computação, aparece em ética algorítmica.
Caminhos sugeridos para resolver o problema
Unificar a linguagem entre Estatística e Ciência de Dados é essencial para evitar retrabalho, melhorar avaliação de projetos, fortalecer colaboração interdisciplinar e ampliar o impacto das áreas. O texto encerra propondo transformar a atual “Torre de Babel” terminológica em uma ponte sólida entre comunidades.