
A inteligência artificial (IA) vem transformando diversos setores da economia, e o mercado imobiliário não é exceção. Pesquisadores vinculados ao grupo CIDENG, da Universidade Federal de Ouro Preto (UFOP) e da Universidade Federal de Juiz de Fora (UFJF), realizaram uma revisão sistemática da literatura sobre o uso de técnicas de aprendizado de máquina (machine learning) na previsão de preços de imóveis.
O estudo, publicado recentemente na revista Computational Economics, identificou as principais abordagens utilizadas na área e apontou desafios relevantes para o avanço do tema.
Entre os algoritmos mais utilizados na literatura estão modelos amplamente aplicados na ciência de dados, como Random Forest, XGBoost, Regressão Linear e Redes Neurais Artificiais. Esses modelos são capazes de aprender padrões a partir de grandes volumes de dados e realizar previsões com alto grau de acurácia.
Um dos objetivos da pesquisa foi verificar se o tamanho da base de dados influenciava a precisão dos modelos. No entanto, os autores não observaram uma tendência clara. Isso reforça uma ideia importante: a quantidade de dados é relevante, mas a qualidade dos dados é ainda mais decisiva para o bom desempenho dos algoritmos. Aspectos como confiabilidade, atualização e representatividade das informações podem impactar mais do que o volume de dados disponível.
De acordo com a análise dos autores, os fatores mais considerados no valor de um imóvel, em ordem, são:
- Características físicas do imóvel, como área construída, número de quartos e vagas de garagem;
- Localização, que se destacou como o fator mais decisivo em diversos estudos;
- Custos financeiros recorrentes, como condomínio e IPTU.
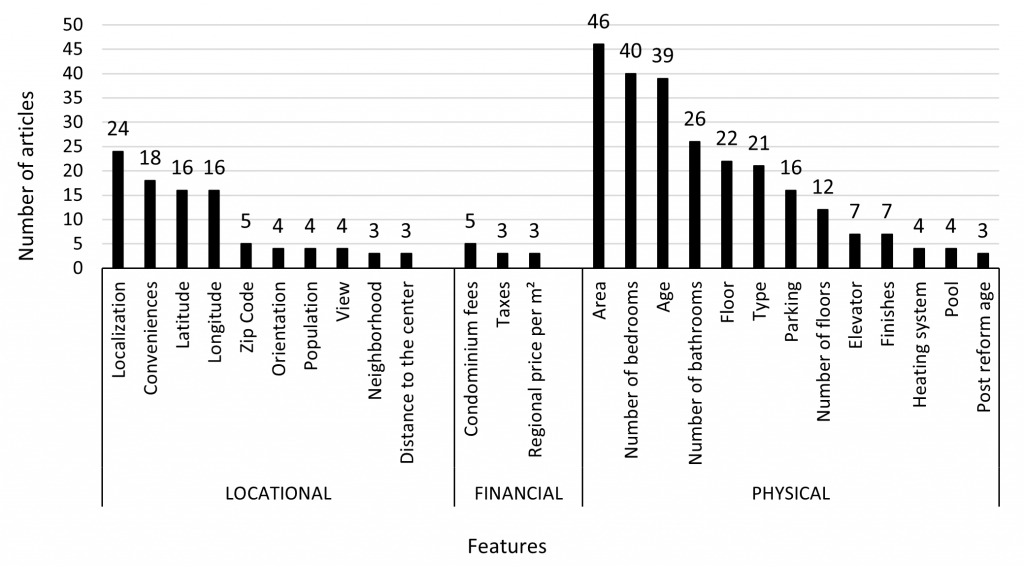
Figura 1 – Fatores mais usados pelos modelos de IA para estimar o preço dos imóveis.
O artigo também apontou limitações importantes nos trabalhos revisados. Muitos estudos utilizam dados provenientes de sites de anúncios imobiliários, que nem sempre refletem o valor real de venda dos imóveis, comprometendo a confiabilidade das previsões.
Além disso, os pesquisadores identificaram um problema sério: a existência de anúncios falsos em plataformas online. Em alguns casos, foram observadas práticas antiéticas de agências imobiliárias, como anúncios de imóveis inexistentes ou indisponíveis, com o propósito de apenas atrair usuários para seus sites. Essas distorções enganam o consumidor e também afetam negativamente o treinamento dos modelos de IA, que passam a aprender com dados imprecisos ou enganosos.
O artigo contribui para o entendimento das tendências atuais no uso de IA no setor imobiliário e destaca lacunas importantes a serem exploradas por pesquisas futuras, como a incorporação da variável “tempo” de forma mais rigorosa e a melhoria das fontes de dados utilizadas.
A publicação completa pode ser acessada no link:
🔗 https://link.springer.com/article/10.1007/s10614-025-10983-4